Apica today added the ability to centralize the management of telemetry data collected from multiple types of agents to its Apica Ascent observability platform.
Ranjan Parthasarathy, chief product and technology officer for Apica, said the addition of Fleet Data Management will also make it simpler to normalize telemetry data collected from across increasingly complex application environments regardless of what type of agent is used to collect data.



DevOps teams can make use of metadata to identify logs, traces and metrics within that pool of normalized data, he added. That approach enables DevOps teams to also reduce the total cost of observability because telemetry data is not being collected indiscriminately, added Parthasarathy.
Finally, DevOps teams gain flexibility because Fleet Data Manager can also be used to automatically configure agents. As a result, DevOps teams are not as tied to rigid configurations, leading to errors and reduced performance, or locked into proprietary instances of agent software, said Parthasarathy.
Fleet Data Management today supports agents such as OpenTelemetry Collector, Fluent-bit, OpenTelemetry Kubernetes Collector, and Telegraf spanning hybrid IT environments, all of which can be automatically configured. That’s crucial because the simpler it becomes to instrument applications using agents, the more likely it becomes they will embrace observability, noted Parthasarathy.
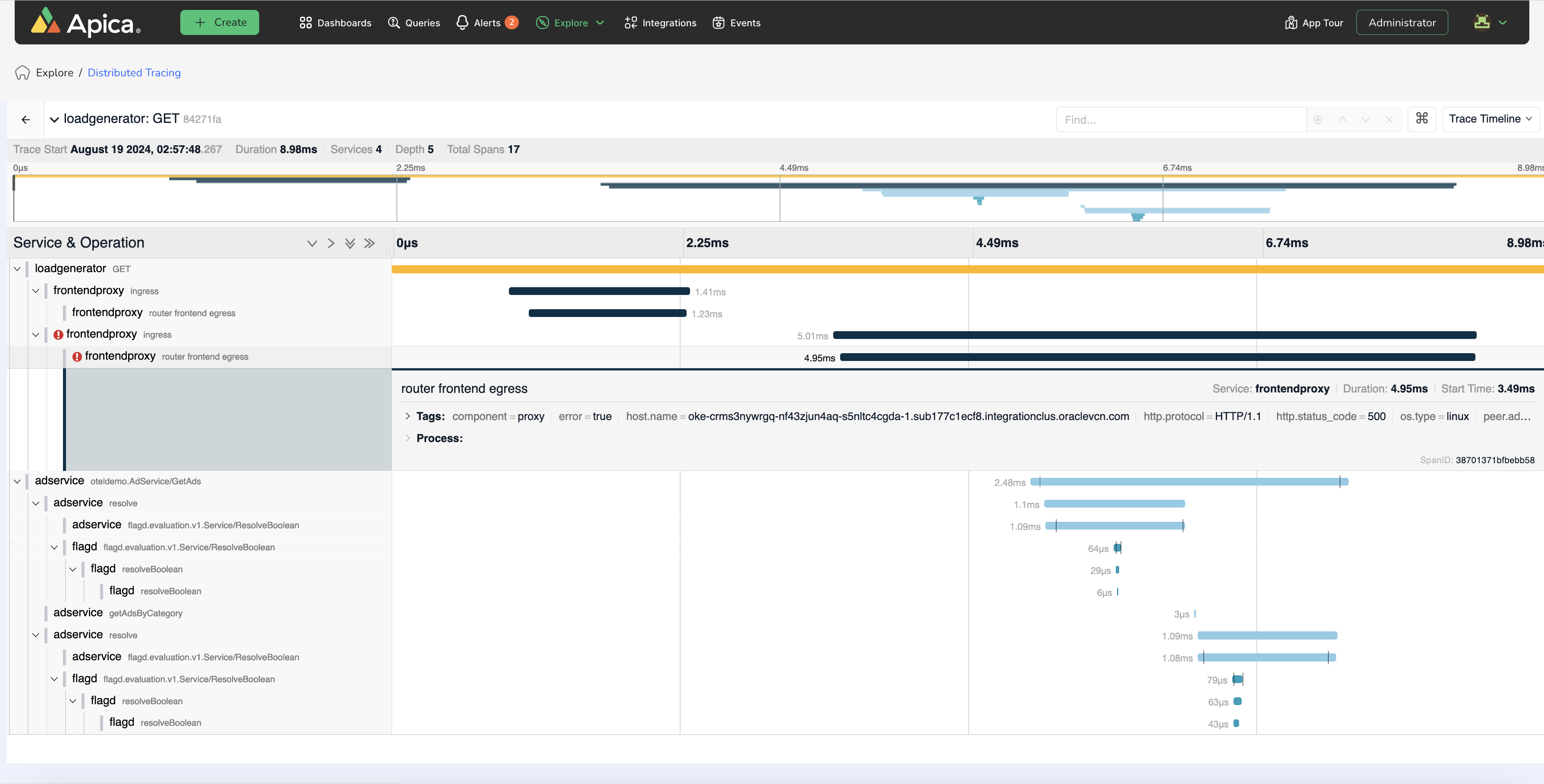
At the core of the Apica Ascent platform is an indexing engine built on top of a Kubernetes platform that aggregates data such as logs, traces and network packets from multiple sources. Designed to be deployed anywhere, the platform reduces storage costs by trimming excess data that can be stored in a data lake it provides or, if a customer prefers, a third-party data lake. Last year, Apica acquired Logic.ai to add a data fabric capability to its core platform.
As more DevOps teams move beyond simply monitoring a set of pre-defined metrics, they are encountering challenges with everything from managing agents to storage costs that are spiraling out of control. In addition, DevOps teams may not have the knowledge and expertise required to craft the queries needed to determine the root cause of an issue. In theory, machine learning algorithms will automatically surface critical alerts, but there will always be a need to understand how an application environment is constructed if a DevOps team hopes to optimize it or, when necessary, resolve an issue.
Despite those challenges, it’s only a matter of time before most IT organizations start to unify observability data within a single platform. That will make it simpler for them to collaborate across teams and should result in fewer disruptions as IT issues are discovered more quickly. Observability platforms are the first critical step toward eventually breaking down many of the silos that today conspire to make managing IT more challenging than anyone would like.
The issue, as always, is not only finding a way to fund the acquisition of an observability platform but also acquiring the skills and expertise required to master it.
