Fauna has added an ability to maintain strict enforcement of schema to its document-relational database using a declarative language that makes it simpler to update databases within the context of a DevOps workflow.
While Fauna has enabled IT teams to extend a document database to add tables and rows typically requiring a relational database, Fauna Schema adds the structure, enforcement and reliability of a schema typically associated with traditional relational databases.
Fauna CEO Eric Berg said the addition of the approach strengthens the case of using a Fauna database that makes it simpler to streamline the management of databases that can be used to support multiple types of applications. In addition, Fauna now enables database schemas to evolve as the needs of the business evolve using a new Document Types capability that allows developers to define and enforce schema structures directly within the database. Document Types can support both static and dynamic typing, enabling developers to start with a schemaless document database before adding stricter type controls in a way that doesn’t require a database to be taken offline, said Berg.
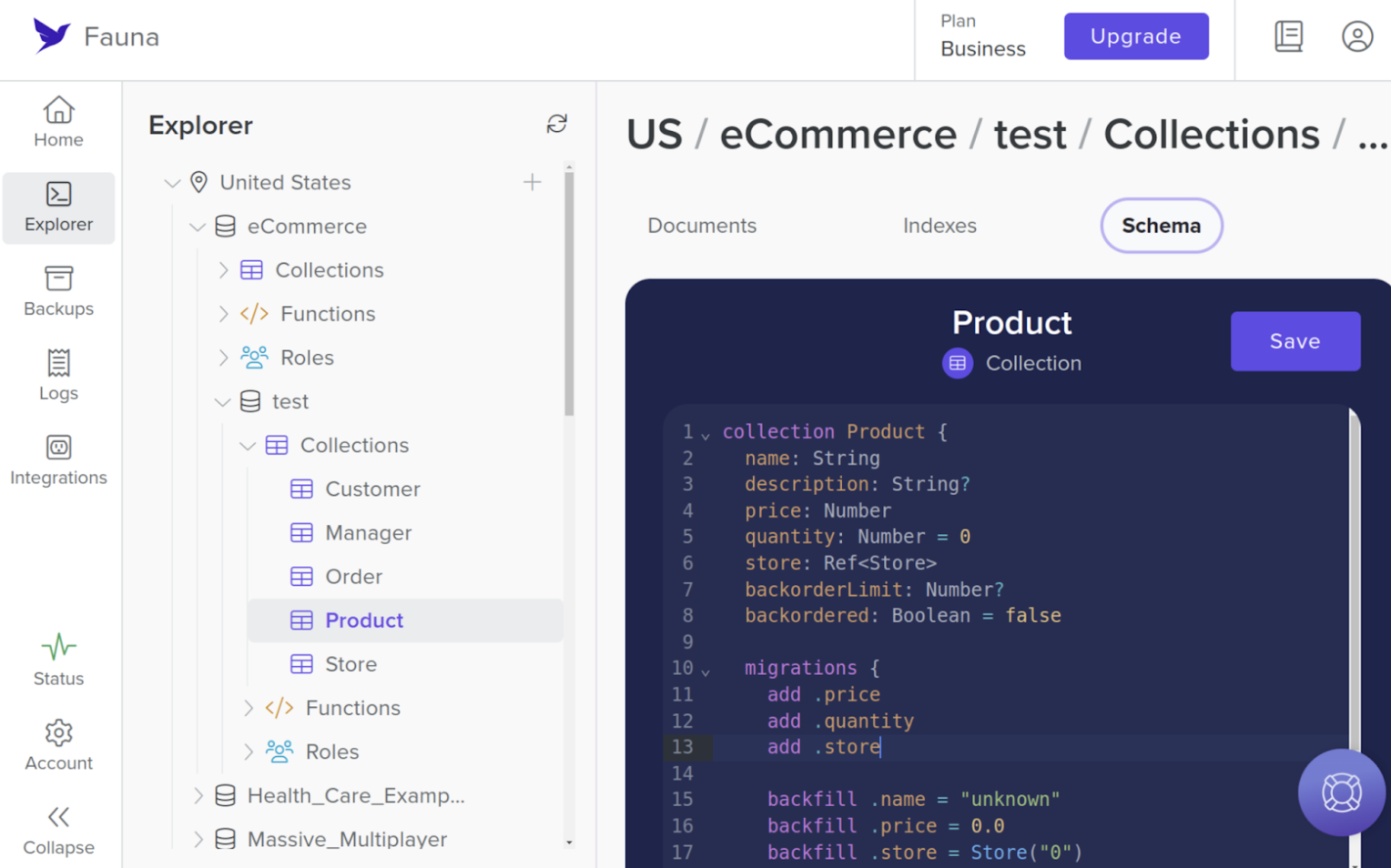
At the core of that capability is the Fauna Schema Language (FSL), which enables developers to declaratively define their domain models, access controls, and business logic in a human-readable language in a set of files that can be managed alongside their application code.
Using a code repository such as GitHub, DevOps teams can now coordinate schema and application code updates via a continuous integration/continuous delivery (CI/CD) pipeline. Additionally, IT teams can leverage infrastructure-as-code (IaC) tools such as Pulumi and Terraform to automate the deployment and management of their Fauna database configuration.
Fauna also added a Computed Fields capability that allows the values of fields in documents to be dynamically generated based on expressions defined by the user. That approach allows developers to create fields whose values are calculated at the time of query to enable a dynamic composition of objects and field values. These fields can be indexed, providing even greater flexibility in query patterns so developers can accurately define their data model in the database versus requiring them to be defined in mapping layers running outside of the database.
Encoding that database logic within the database allows development teams to define cross-collection joins and subqueries as an element of their schema design to dynamically generate data, and object models in real-time. That capability avoids the performance disadvantages inherent in a data denormalization strategy required by other document databases.
It’s not clear to what degree IT organizations are moving to consolidate databases, but with the rise of document databases, it has become relatively simple for developers to add a database to just about any type of application. The challenge organizations encounter is that as document databases evolve, they become more challenging to manage. It’s not uncommon for developers to pass the responsibility for managing document databases on to a DevOps team that often has a vested interest in consolidation.
After all, the more databases based on disparate architectures there are to manage the more challenging it becomes to manage DevOps workflows at any level of meaningful scale.
