This article illustrates how to deploy an application into a Hadoop cluster using GitLab/Jenkins/Spark application.
In this article, we will cover the following:
- Auto-triggering Jenkins build when code is committed in Git.
- Pulling the latest code from the repository through Jenkins.
- Building, compiling and packaging the “.jar” using SBT tool.
- Uploading the .jar to the Nexus repository with defined version.
- Pulling the versioned jar and dependent files from Nexus repository to server.
- Deploying the versioned “.jar” file through Spark job into Hadoop cluster.
Getting Started
The following must be performed first:
- Download and install Java 1.8.
- Install Jenkins.
- Integrate GitLab and Jira.
- Install SBT.
- Create the Hadoop cluster: Hadoop and Spark.
End to End Steps in Detail
When a developer pushes code to GitLab, Jenkins will trigger a predefined job using webhooks.
The Jenkins job will pull the code from version control using Git; it builds the code and makes the package as .jar file using the build tool SBT. This .jar file can be deployed into a Hadoop cluster with the help of a Spark command.
Once the deployment is completed in the Hadoop cluster, the application will start running in the background.




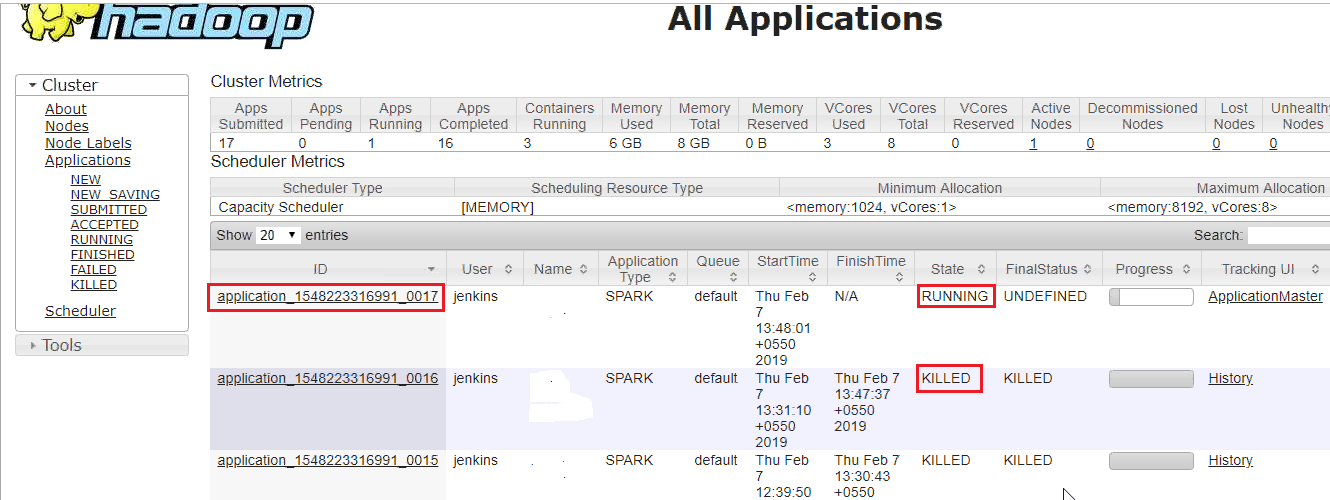
Initially, we can see the current running application in Hadoop (see Figure 1). It has an application ID, which is in a running state.
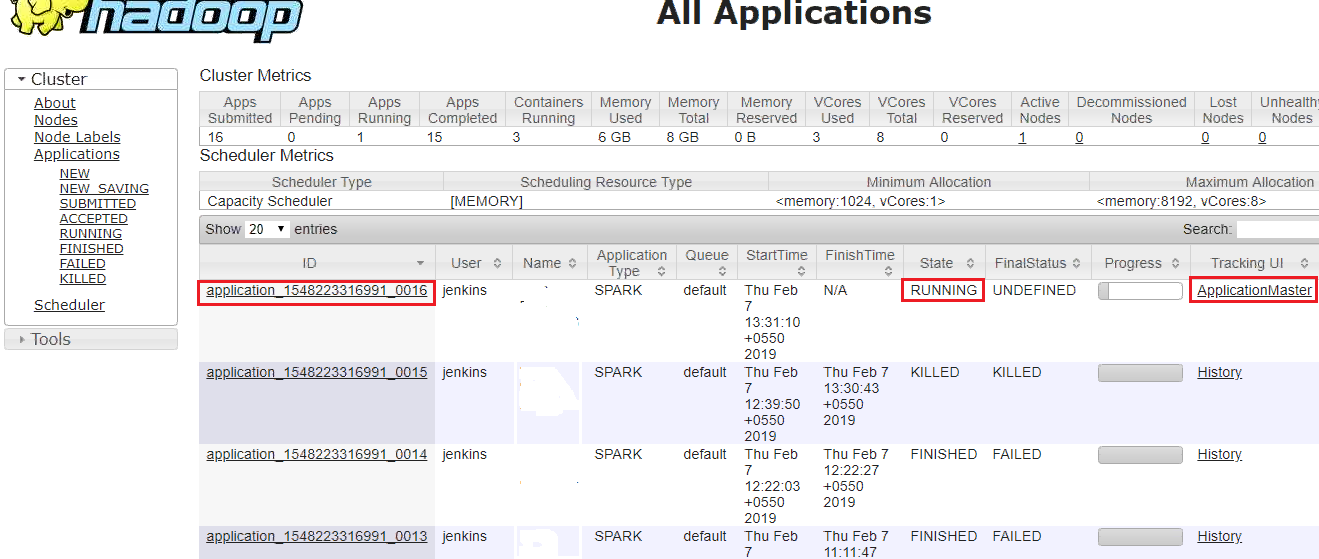
- If we click the tracking UI, which is Application Master, it will navigate into the Spark streaming page.
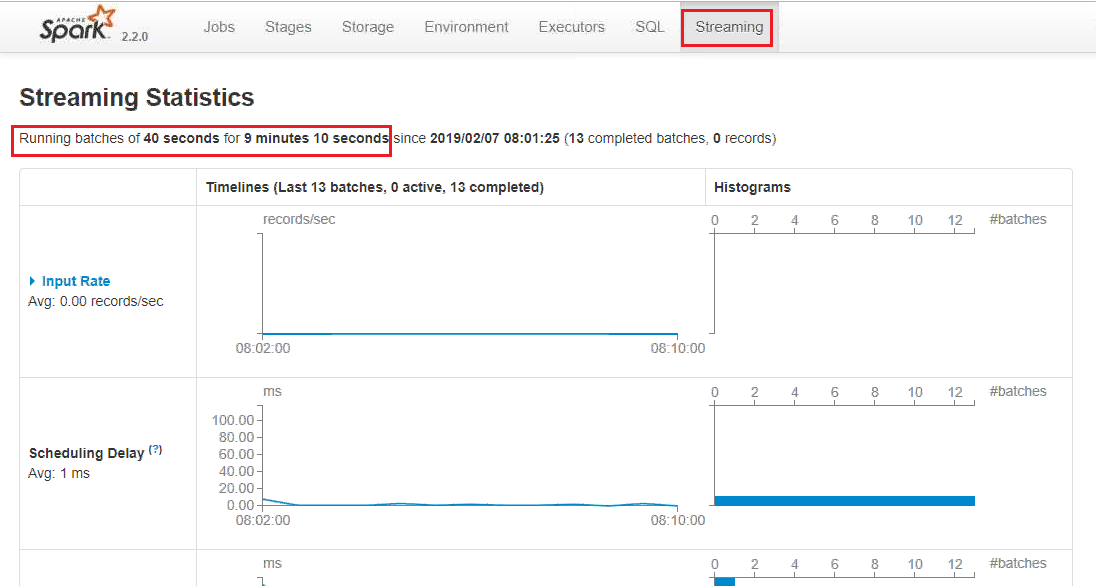
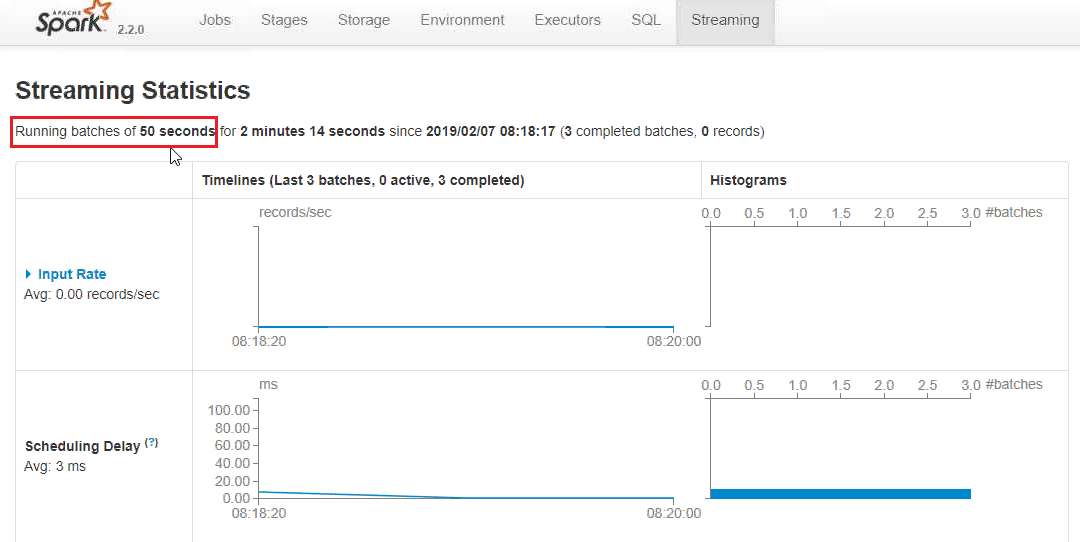
- In Figure 2, we can see batches are running in 40 seconds. For this scenario, we are changing from 40 seconds in the code.
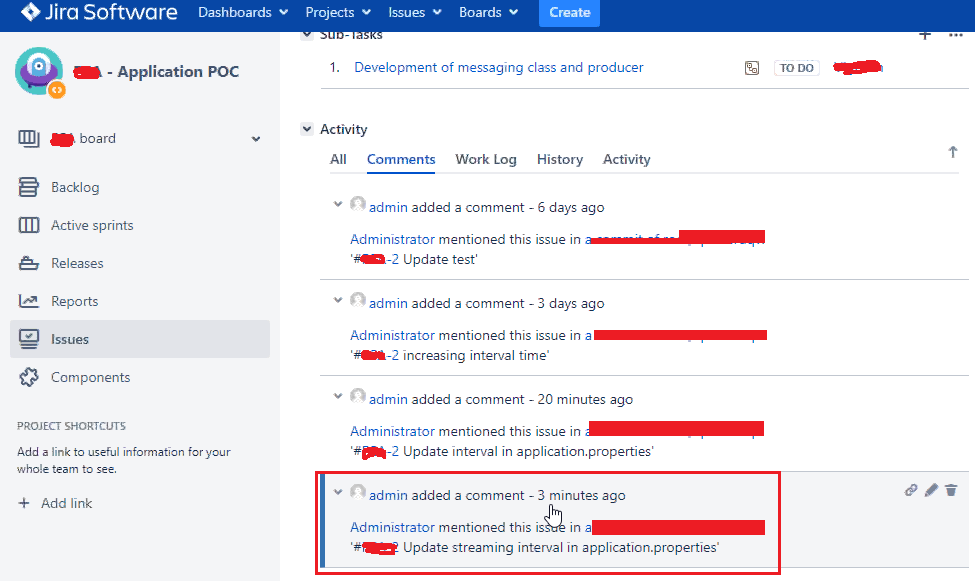
- When a developer makes changes to the code, he will commit in his local machine and test his code, then push to remote repository. I have updated steaming time from 40 to 50 seconds and committed.
- If we can specify the Jira task number in the commit message, the same comment will be updated in the Jira task as below.
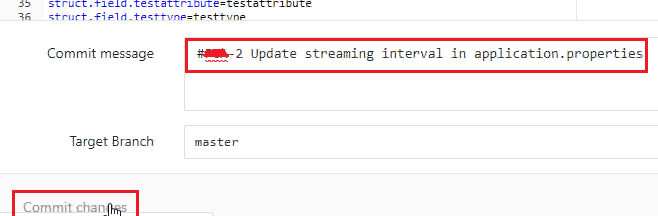
In the Jira application, we can see our commit message as comments.
GitLab and Jira integration process:
- Install Git plugin to pull code from GitHub repository and SBT plugin to build and make a package as a .jar file in Jenkins.
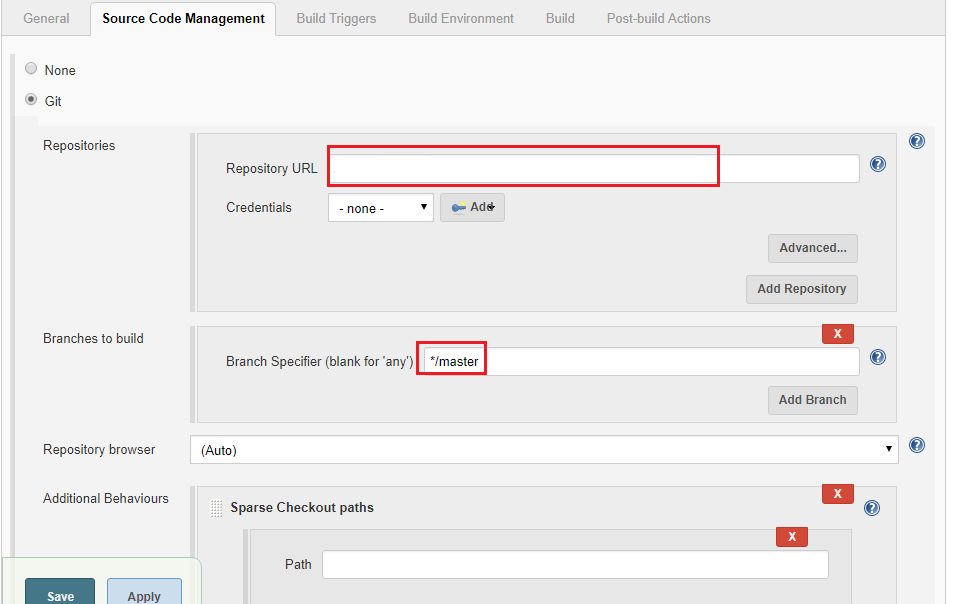
- Configure the Jenkins job under source code management and provide the Repository URL along with credentials and branch details.
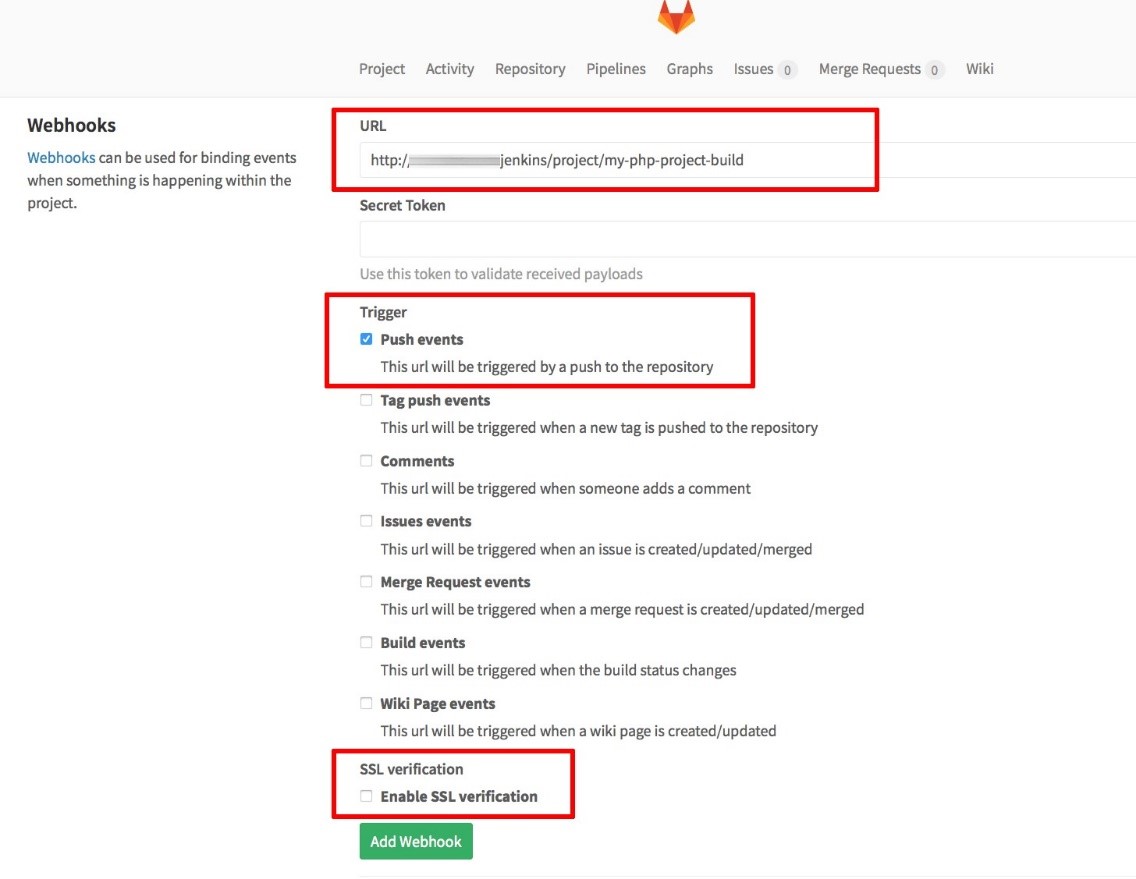
- Optional: Set webhooks to automatically trigger the Jenkins job when the push happens in GitLab.
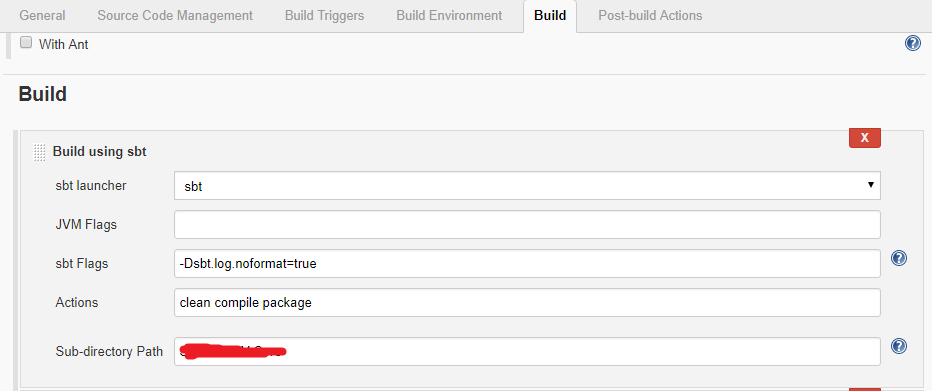
- In the “build” section, add the parameters clean compile package in the Actions field, which will build the code and create a .jar file.
- Once the job has been triggered in Jenkins, monitor the Jenkins console for the next step and errors, if any.
Optional: If we have configured SonarQube, it will analyze the code files and provide the result in the SonarQube dashboard. This allows us to know the code quality, code coverage vulnerabilities and bugs to improve efficiency of code.
- Optional: To maintain the versioning, we can upload our *.jar into Nexus/Artifactory.
- Once .jar has been created, we can keep it in a specific folder and trigger a Spark job. This can be performed by triggering a Spark command from Jenkins. Execute the below command to submit spark job:
# spark-submit –name appName –master yarn –deploy-mode cluster –executor-memory 1g –driver-memory 1g –jars $(echo $dependencyJarDir/*.jar | tr ‘ ‘ ‘,’) –class com.coe.spotter.DQModule –conf spark.driver.extraJavaOptions=../src/main/resources/log4j-yarn.properties –conf spark.sql.warehouse.dir=./spark-warehouse –conf spark.yarn.submit.waitAppCompletion=false app.Jar
|
- Once deployed, we can see the application ID number has been increased.
Timeout in the Spark streaming job has been increased to 50 seconds.